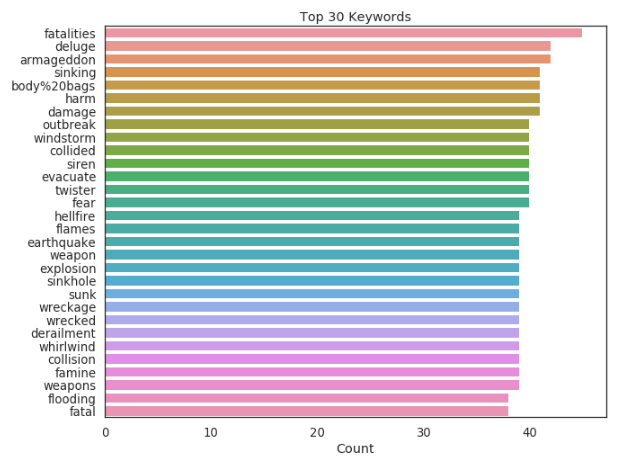
My first foray into NLP! In this notebook I conduct basic EDA to tease out important characteristics of the data, including keyword prevalence, tweet length and author locations. I also utilize the NLTK package to parse common words and stopwords.
Few things that stood out to me:
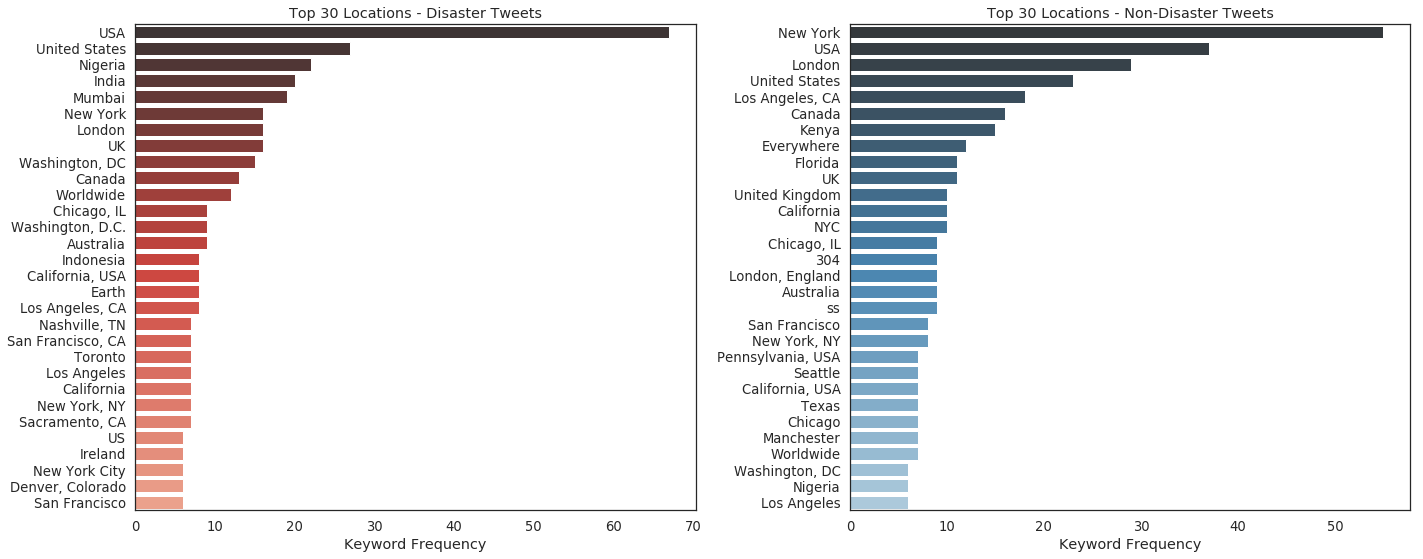
Disaster tweets originate from different locations that non-disaster tweets.
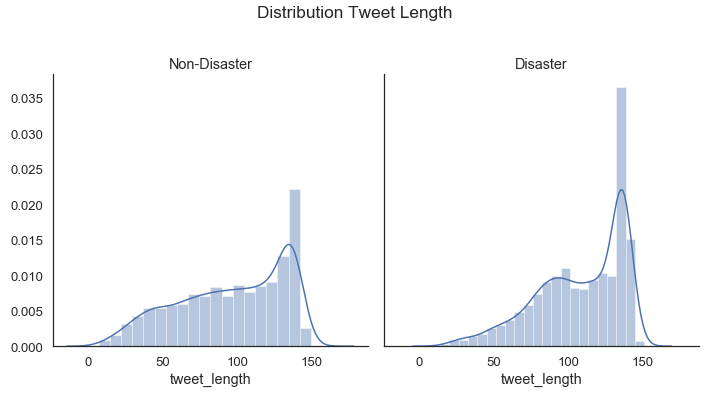
Disaster tweets also tend to be slightly longer.
Check out the full notebook for more interesting findings: