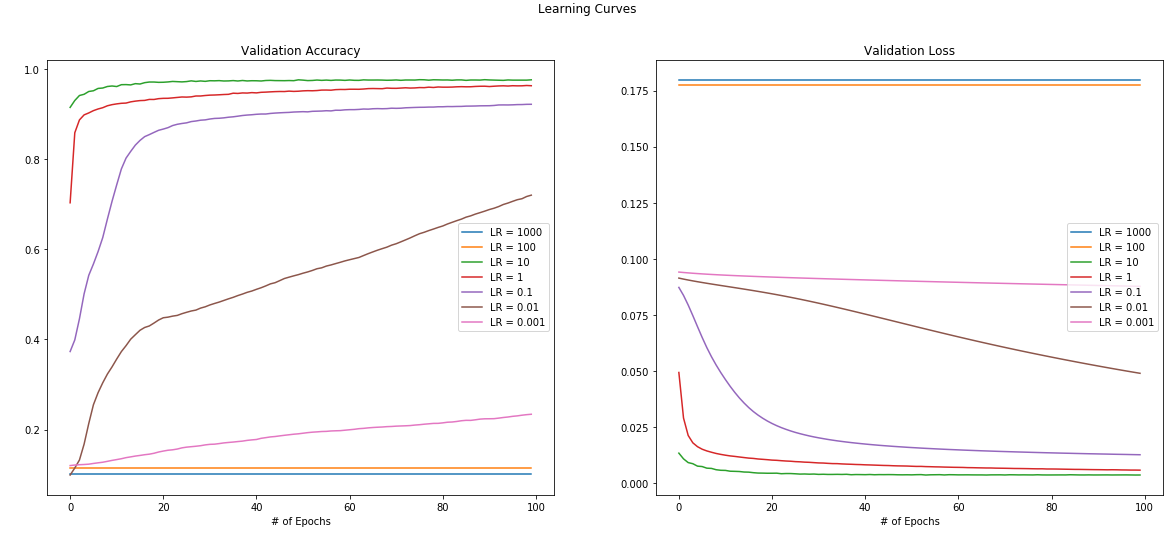
One of my goals for February was to revisit artificial neural networks, a topic that I had touched on briefly during the IBM Data Science Professional Certificate program. Happily, I am currently reading Deep Learning Illustrated by Jon Krohn, so I have plenty of relevant material to review and implement.
I decided to do a deep dive into neural network hyperparameters, namely:
- Batch Size
- Learning Rate
- Activation Functions
- Number of Layers
My goal was to see how adjustments to these hyperparameters impacted the network's ability to learn. Exploration was done in Keras using the classic MNIST dataset.