A few weeks ago, I started working with the Titanic dataset. Initially, I performed a thorough round of exploratory data analysis (view notebook) and I thought I had a handle on what needed to be done.
Well, cue the part where I repeatedly run up against a wall using traditional machine learning approaches. Umpteen rounds of random forest hyperparameter tuning, cobbling together different models, creative feature engineering, categorical variable binning...
After trying (and failing) to score higher than ~78% accuracy using numerous variations of stacked ensembles, I decided to take a step back. Increasing complexity was obviously not increasing model accuracy. Perhaps if I better understood the problem and increased my domain knowledge, I would have a better chance of moving up the leaderboard.
I stumbled across an interesting notebook by Chris Deotte in which he creates a relatively high-scoring model using the Name feature alone: Titanic using Name only. Although parsing his R code was a bit of a challenge, Chris' commentary was extremely clear and logical.
The basic premise is that we can infer family groups based on passenger last name, which is extracted from the Name field. Survival within these so-called "woman-child-groups" is almost always binary - either all members of the WCG die or all survive. Therefore, if a test case is presented for which we can determine family group status, we should predict survival based on the survival of the family group.
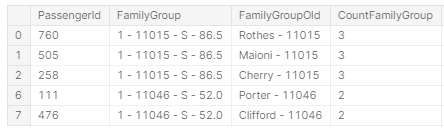
Interestingly, I originally constructed FamilyGroup using passenger last name. However there were a handful of occasions when this resulted in individuals being left out of groups because they had a different last name. For this reason, I selected a different grouping method using Ticket, Embarked and Fare.
At the end of the day, using this group-based strategy in conjunction with the baseline gender-based model in which all men die and all females survive, resulted in an accuracy of 81.3%. Quite an improvement over my overly complex ensembles!
All credit to Chris for the great idea. I really enjoyed exploring his hypothesis and implementing a similar model in Python.